Deferreds are a DataFlow Abstraction.
Posted March 30, 2012This was originally conceived as a response to A Conversation with Guido about Callbacks over at Duncan McGreggor’s blog.
First, a jQuery-ish example of using some callbacks:
1
2
3 =
4
5
6 print
7
8
9
10
11
12
Now this is an absurd example of callback soup. Or is it? I’ve read a lot of JavaScript, and it isn’t really uncommon to see multiple levels of calls which take a callback. The JavaScript actually usually looks cleaner and is easier to read than our contrived Python because JavaScript has multi-statement anonymous functions that can be used to inline the callback definition into the function call. (That feature has other readability side-effects though, such as the pattern of defining a single argument anonymous function to invoke a single, single argument function.)
Now, when you write callbacks like this, it’s no wonder people tend to dislike them. Especially when contrasted with the more straightforward non-callback example.
1 =
2 =
3 =
4 print
4 lines of code vs 8 lines of code (11 including almost mandatory blank lines.) Is it any wonder that Guido prefers this approach? No, absolutely not. That first example is an absolutely terrible but perfectly normal piece of callback using code. Let’s enumerate some of the ways in which it is bad.
- Everything is out of order.
- Excessive indentation. Flat is better than nested, but close is better than far, so nested wins.
- The desire for locality causes function definitions to be scattered among statements.
- You’re defining a lot of non-reusable, non-testable functions.
I’m sure you’ve come up with plenty more of complaints (including non-PEP8 camelCase names) but these are the 4 big points I’d like to discuss further.
Order matters.
Most of us read left to right and top to bottom. Even if your primary language doesn’t read left to right and top to bottom your primary programming language almost certainly does. When we make todo lists we give them an order, items at the top are more important. Shopping lists are sometimes ordered starting with vegetables and moving towards more time fragile things like ice cream, because that’s the way the stores are laid out. Computer programs are written line by line in the order we want instructions executed, because that is how computers work.
Order matters. On first encounters with code order matters a lot.
Related statements should be close.
Locality is the topic of both issues 2 & 3. And it can best be summed up as, related things should be close. It’s the most basic element of organization for everything from kitchens to code.
Anytime you’re reading anything you’ll find yourself glancing back to reread a few lines, or sentences, or even words as soon as you’ve encountered something that you don’t understand or doesn’t quite make sense. The further you have to look the longer it’s going to take to get your answer.
Reduce, Reuse, Retest.
We write functions to enhance the readability, and testability of our code. We reduce the size of large functions by breaking them up into higher level discrete steps and creating functions to encapsulate those actions. We reuse common code by creating more functions. We retest, ok well retest doesn’t make much sense, but we increase testability by concentrating functionality into smaller more well defined units.
You would never inline all the socket calls necessary to make an HTTP request. Maintainable software is built out of well defined reusable and testable abstractions, and there is no reason that callbacks should not also be reusable and testable as much as possible.
There is a better way.
I’ll admit, I have a love/hate relationship with callbacks. I view them as a necessary evil to do event-driven programming. There is of course a better way to think about callbacks and you may have already guessed it. Deferreds and Dataflow programming. A lot of people use deferreds for the first time much the same way they use plain callbacks.
1 =
2
3
4 =
5
6 print
7
8 =
9
10
11 =
12
13
14
Now, this example, though still contrived is not unrealistic, it is in fact perfectly functional and probably exists in more than a few Twisted using code bases. Of course it’s terrible for all the same reasons our plain callback example was terrible.
So clearly it is not the better way. So what is?
Deferreds as a dataflow abstraction.
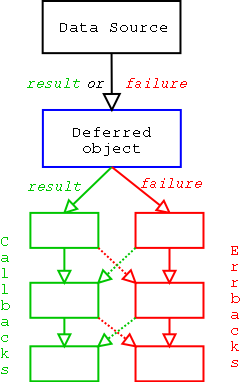
Here you have a acyclic directed graph of data through the callback chain. The individual operations being performed is less important than the flow of information through the structure. An event causes a result to be available, it is put into the deferred and moves along the directed graph through the callback chain until an error is encountered. Then we move to the errback chain will proceed until the error has been handled at which point we can go back to the callback chain, or until we run out of errbacks.
The result from one operation flows directly into the next.
1
The above is a dataflow program. Our imperative example from earlier is not, because the grouping of operations is a side effect of style, any number of operations could be interspersed which may or may not have side effects that influence future operations.
1 =
2
3
4
5
Now, everything is in order, related operations are close, and the structure of higher level operation is broken up into discrete and independently testable units.
By this point I hope I have made it obvious about why “thinking in Deferreds” is better than “thinking in callbacks” but if I have not imagine this example from a fictional streaming API and maybe you’ll understand why “thinking in dataflows” is a good thing.
1
2
3
4
5
6
7
8
Now we have encapsulated not only how we handle one result, but rather a potentially infinite number of events. Now we have the potential for building some realtime distributed systems.